实验室8篇论文被国际计算机视觉与模式识别会议CVPR 2025接收
IRIP实验室今年共有8篇论文被国际计算机视觉会议CVPR 2025接收!CVPR是由IEEE主办的计算机视觉及人工智能等领域最具影响力和最重要的国际顶级会议之一。此次会议有13008篇的有效大会论文投稿,共录取2878篇论文,率用率为22.1%。此次会议将于美国田纳西州纳什维尔召开。
接收论文简要介绍如下:
1.Diffusion-4K: Ultra-High-Resolution Image Synthesis with Latent Diffusion Models. (Jinjin Zhang, Qiuyu Huang, Junjie Liu, Xiefan Guo, and Di Huang)
本文提出了Diffusion-4K,一个采用文本到图像的扩散模型直接生成超高分辨率4K图像的新型框架。其核心创新包括:(1) Aesthetic-4K基准测试:我们精心筛选了图像以及由GPT-4o生成的文本,创建了一个高质量的4K图像生成数据集。此外,我们引入了GLCM评分和压缩比等指标来评估高分辨率图像生成的细节,并结合FID、美学评分和CLIPScore等整体度量指标,构建了超高分辨率图像生成的全面评估基准。(2) 基于小波变换的潜在空间增强:我们提出了一种基于小波变换的潜在空间特征增强方法,用于直接训练具有高度真实的4K图像生成模型,适配于各种主流的潜在扩散模型方法。通过我们的方法,能够直接生成具备高度细节纹理的4K图像。Diffusion-4K在高质量图像合成和文本提示遵从性方面表现出色,尤其是基于大规模参数量的扩散模型(如SD3-2B和Flux-12B),取得了令人印象深刻的图像生成效果。大量的基准测试以及实验结果证明了Diffusion-4K生成超高分辨率4K图像的有效性。

2.Towards Training-free Anomaly Detection with Vision and Language Foundation Models. (Jinjin Zhang, Guodong Wang, Yizhou jin, and Di Huang)
异常检测在实际应用中具有重要价值,特别是在工业质量检验等领域。然而,大多数现有方法侧重于检测局部结构异常,而忽视了包含逻辑约束的组合异常。在本文中,我们提出了基于多模态基础模型的通用异常检测框架LogSAD,用于同时检测逻辑和结构异常,并且无需额外训练。首先,我们提出了“思维匹配”架构,利用先进的大型多模态模型(如GPT-4V)生成匹配建议,形成异常检测的感兴趣特征集合以及组合规则。其次,我们提出了多粒度的异常检测器,包括基于视觉和语言基础模型的区域匹配、感兴趣特征集匹配和组合关系匹配。最后,我们提出了多粒度检测器校准模块,对来自不同粒度检测器的异常评分进行对齐,然后采用策略集成进行最终决策。综上所述,我们的方法在统一框架内同时解决了逻辑和结构异常检测问题,并在无需训练的情况下取得了超越监督学习方法的先进结果,展示了其强大的鲁棒性和有效性。

3.CoSDH: Communication-Efficient Collaborative Perception via Supply-Demand Awareness and Intermediate-Late Hybridization. (Junhao Xu, Yanan Zhang, Zhi Cai, Di Huang)
多智能体协同感知通过利用来自多个智能体的信息来增强感知能力,被认为是解决自动驾驶中单车感知能力弱问题的根本方法。然而,现有的协同感知方法面临着通信效率和感知精度之间的困境。为此,我们提出了一种新颖的基于供需感知与中晚混合协作的协同感知框架,称为CoSDH。供需感知用于优化协作区域的选择以减少不必要的通信,中晚期混合协用于减少低带宽约束下的精度下降。实验结果表明,CoSDH 在多个数据集上均实现了当前最优的检测精度与带宽权衡,并在模拟真实通信带宽限制的条件下精度显著优于现有方法,展现了其在实际应用中的潜力。

4.GaussianIP: Identity-Preserving Realistic 3D Human Generation via Human-Centric Diffusion Prior. (Zichen Tang, Yuan Yao, Miaomiao Cui, Liefeng Bo, Hongyu Yang)
随着高效的3D表示和2D提升方法(如分数蒸馏采样SDS)的发展,文本引导的3D人体生成技术取得了显著进展。然而,现有方法存在训练时间过长的问题,且生成的图像往往缺乏精细的面部和服装细节。本文提出了GaussianIP,一个有效的两阶段框架,旨在从文本和图像提示中生成能够保留面部id特征的逼真3D人体。我们的核心思想是利用以人为中心的知识来助力生成过程。在第一阶段,我们提出了一种新颖的自适应人体蒸馏采样方法(AHDS),能够快速生成与图像提示保持高度身份一致的3D人体,并且具备逼真的外观。与传统的SDS方法相比,AHDS更好地契合了以人为中心的生成过程,显著减少了训练步骤,同时提升了视觉质量。为了进一步提升面部和服装区域的视觉质量,我们在第二阶段设计了一种多视角一致的纹理精细化机制(VCR)。具体而言,该策略迭代地对第一阶段输出的多视角图像进行加噪与去噪,实现了对纹理细节的优化,并通过互注意力和相对距离引导的注意力融合策略确保跨视图的3D纹理一致性。随后,直接使用精细化后的图像进行重建,可以获得更高质量的3D人体。大量实验表明,GaussianIP在视觉质量和训练效率方面均优于现有方法,特别是在生成具有身份保持性的结果方面表现尤为突出。

5.APHQ-ViT: Post-Training Quantization with Average Perturbation Hessian Based Reconstruction for Vision Transformers. (Zhuguanyu Wu, Jiayi Zhang, Jiaxin Chen, Jinyang Guo, Di Huang, and Yunhong Wang)
目前基于块重建的训练后量化(PTQ)方法已在CNN中较为成熟,但是直接将它们应用于视觉Transformer中表现不佳。其原因在于,这些方法对于块输出的重要性估计不准确。此外,目前面向视觉Transformer的训练后量化方法,对于范围较广的Post-GELU激活量化误差较大,导致精度损失严重。针对重要性估计不准确的问题,我们提出了一种基于平均扰动海森的重要性估计准则,并以此构建块重建的损失函数。与之前的方法相比,平均扰动海森损失使用了更少的假设与近似,并且能够使得优化过程更加稳定。针对Post-GELU激活量化误差较大的问题,我们提出了一种MLP重构方法。该方法使用平均扰动海森构建损失函数,在逐块重建过程中显著减小了激活范围,同时将GELU激活函数替换为ReLU,进一步提升模型精度。广泛的实验表明,我们的方法优于目前最先进的视觉Transformer训练后量化方法,特别是在低比特情形下。

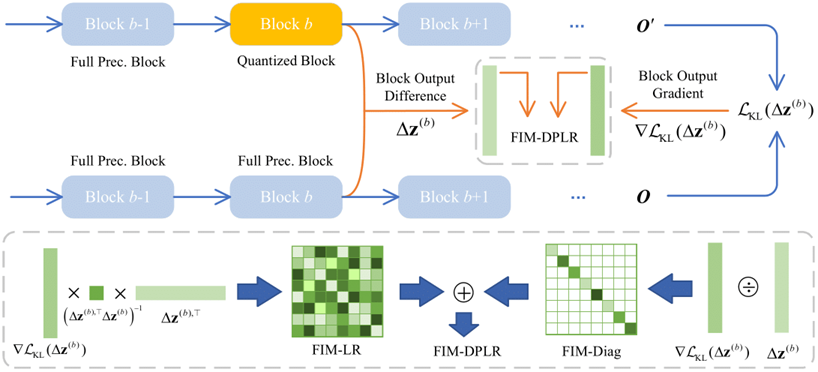
6.FIMA-Q: Post-Training Quantization for Vision Transformers by Fisher Information Matrix Approximation. (Zhuguanyu Wu, Shihe Wang, Jiayi Zhang, Jiaxin Chen, and Yunhong Wang)
目前对于视觉Transformer的训练后量化(PTQ)方法在超低比特中精度损失严重。我们仔细分析了目前广泛使用的基于海森的量化损失,并指出了这种方法的局限性与不准确性,从而提出了一种基于费舍信息矩阵(FIM)的量化损失。在逐块量化的PTQ流程中,由于完整的 FIM规模过大,所以我们建立了FIM与KL散度之间的关系,从而在重建期间对FIM进行近似并快速计算量化损失。根据FIM与KL散度之间的关系,我们分别提出了对FIM的对角近似、秩一近似、低秩近似,以及对角加低秩(DPLR)近似四种方案。可视化结果与实验结果表明,对FIM使用DPLR近似所构造的损失函数,在不同视觉Transformer架构、不同任务中,均取得了最优的结果。
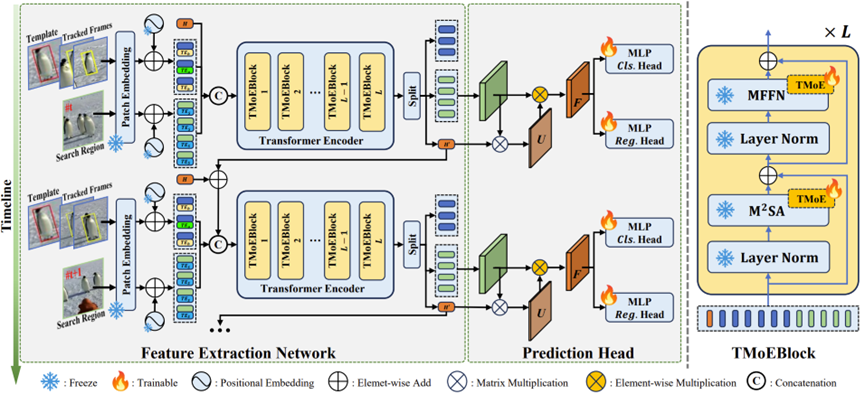
7.SPMTrack: Spatio-Temporal Parameter-Efficient Fine-Tuning with Mixture of Experts for Scalable Visual Tracking. (Wenrui Cai, Qingjie Liu and Yunhong Wang)
现有的one-stream通用视觉跟踪算法使用普通自注意力机制进行模板与搜索图像间的关系建模,但单一的注意力操作不足以处理不同的图像块间关系,例如:目标前景区域容易受到背景区域干扰、目标的关键边缘区域容易被忽视等。目前有跟踪器针对特定的图像块关系建模进行针对性地设计,但缺乏泛化能力,同时也无法挖掘隐藏的关系模式。为了解决以上问题,本文提出了适用于视觉跟踪任务的混合专家模块TMoE,并基于该模块提出了新的跟踪器SPMTrack。TMoE使用更细粒度的线性层作为专家,同时应用于注意力层和前馈神经网络层,通过更灵活的专家组合实现不同关系模式的动态处理。我们将TMoE作为参数高效微调的手段,同时在SPMTrack引入时空上下文建模,在仅需训练约30%的参数的情况下在LaSOT、GOT-10K等7个数据集上超越或达到了目前的最优性能。
8.SeriesBench: A Benchmark for Narrative-Driven Drama Series Understanding. (Chenkai Zhang, Yiming Lei, Zeming Liu, Haitao Leng, Kai Li, Tingting Gao, Qingjie Liu, and Yunhong Wang)
以往评估多模态大模型视频理解能力的基准通常只关注独立的视频,并仅评估视频中的“视觉元素”,如人的动作和物体状态。实际上,现在流行的视频通常包含复杂且连续的剧情,并通常以系列的形式呈现。为了解决这一挑战,本文提出了SeriesBench,一个由105个精心挑选的以剧情为驱动的系列组成的基准,涵盖28个需要深入叙事理解来解决的任务。具体而言,本文首先选择了多样化的剧情系列视频,涵盖广泛的品类。然后,引入了一种全新的长篇剧情标注方法,并结合完整信息转换法,将手动注释转换为多样化的任务格式。为了进一步增强模型在系列中对情节结构和人物关系的详细分析能力,本文提出了一个新的剧情双链推理框架,即PC-DCoT。在SeriesBench上的大量实验结果表明,现有的MLLMs仍然面临在理解叙事驱动系列方面的显著挑战,而PC-DCoT使这些MLLMs能够实现性能提升。
