实验室4篇论文被国际计算机视觉会议ICCV 2023接收
IRIP实验室今年共有4篇论文被国际计算机视觉会议ICCV 2023接收!ICCV是由IEEE主办的计算机视觉及人工智能等领域最具影响力和最重要的国际顶级会议之一。此次会议约有8000篇的大会论文投稿,共录取2160篇论文。此次会议将于法国巴黎召开。
接收论文简要介绍如下:
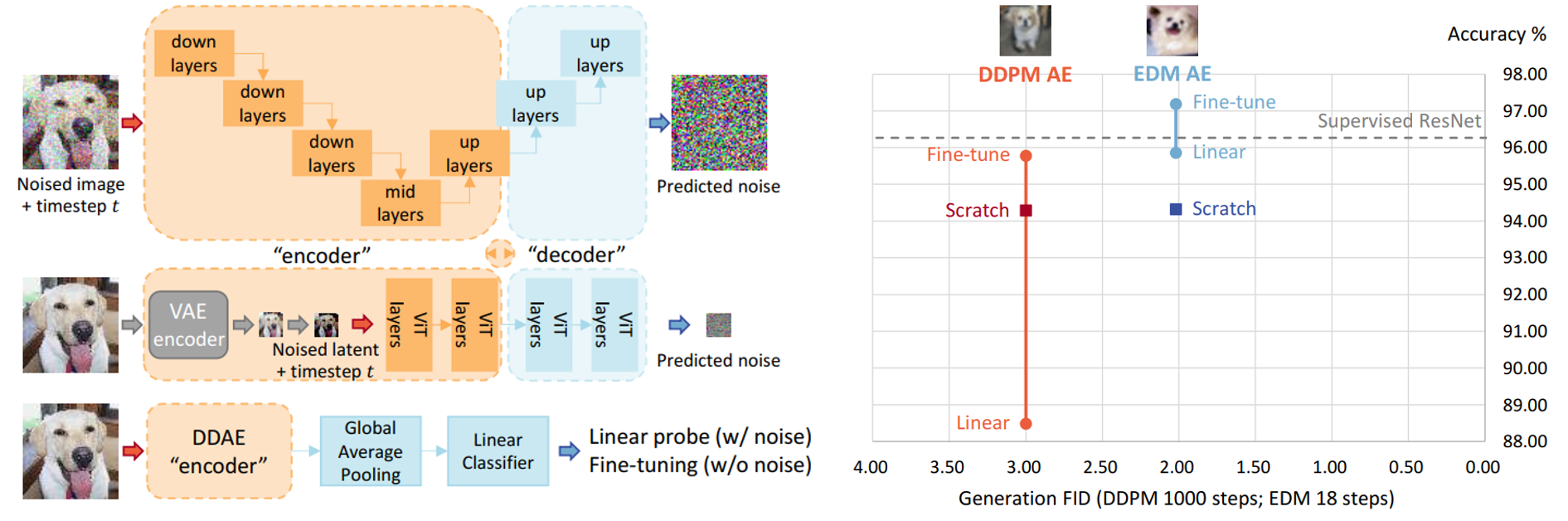
1. Denoising Diffusion Autoencoders are Unified Self-supervised Learners (Weilai Xiang, Hongyu Yang, Di Huang, and Yunhong Wang) oral
受生成式预训练和去噪自编码器启发,本文研究扩散模型能否通过图像生成预训练获得判别能力。本文发现扩散模型中的网络(去噪扩散自编码器,DDAE)已可在中间层学习到强线性可分的特征表示,而无需额外的目标函数或框架修改。为验证此观察,本文在图像分类数据集上进行线性探测和微调实验。本文提出的基于扩散模型的方法在CIFAR-10和Tiny-ImageNet数据集上分别获得了95.9%和50.0%的线性探测分类精度,并首次与掩码自编码器和对比学习等方法相媲美。
Inspired by generative pre-training and denoising autoencoders, this paper investigates whether diffusion models can acquire discriminative capabilities by pre-training on image generation. The paper shows that the networks in diffusion models, namely denoising diffusion autoencoders (DDAE), have already learned strongly linear-separable representations at its intermediate layers without auxiliary objectives or modifications. To verify this, we perform linear probe and fine-tuning evaluations on image classification datasets. Our diffusion-based approach achieves 95.9% and 50.0% linear probe accuracies on CIFAR-10 and Tiny-ImageNet, respectively, and is comparable to masked autoencoders and contrastive learning for the first time.
2.Unilaterally Aggregated Contrastive Learning with Hierarchical Augmentation for Anomaly Detection (Guodong Wang, Yunhong Wang, Jie Qin, Dongming Zhang, Xiuguo Bao, and Di Huang)
异常检测旨在检测偏离正常训练分布的样本,在安全苛求的应用中显得至关重要。由于难以收集涵盖所有异常类别的数据,一个更实际的研究方向是仅依赖正常样本数据来检测异常。尽管近期的自监督学习方法通过创建虚拟负样获得了显著的性能提升,但这些方法的训练目标并不完全符合异常检测的核心思想:紧凑的正常数据分布和发散的异常数据分布。本文提出了单类聚集对比学习,兼顾异常检测对于数据分布的两个要求。启发于课程学习,本文提出层级数据增广,从底层到高层施加逐级增强的数据增广,提高正常样本分布的紧凑度。此外,考虑到对比学习中的数据增广存在引入异常样本的风险,本文进一步提出软聚集机制确保分布的纯净度。在单类别、无标签多类别和有标签多类别三种实验场景下证明了方法的有效性。
Anomaly detection (AD), aiming to detect samples that deviate from the training distribution, is essential in safety-critical applications. Due to the intractability of collecting all kinds of anomalies, it is practical to study the setting where outlier detectors are developed solely based on in-distribution data. Though recent self-supervised learning based attempts achieve promising results by creating virtual outliers, their training objectives are less faithful to AD which requires both a concentrated inlier distribution and a dispersive outlier distribution. In this paper, we propose Unilaterally Aggregated Contrastive Learning with Hierarchical Augmentation (UniCon-HA), in consideration of both the above requirements. Specifically, we explicitly encourage the concentration of inliers and the dispersion of virtual outliers via supervised and unsupervised contrastive losses, respectively. Considering that standard contrastive data augmentation for generating positive views may induce outliers, we additionally introduce a soft mechanism to re-weight each augmented inlier according to its deviation from the inlier distribution, to ensure a purified concentration. Moreover, to prompt a higher concentration, inspired by curriculum learning, we adopt an easy-to-hard hierarchical augmentation strategy and perform contrastive aggregation at different depths of the network based on the strengths of data augmentation. Our method is evaluated under three AD settings including unlabeled one-class, unlabeled multi-class, and labeled multi-class, demonstrating our consistent superiority over other competitors.

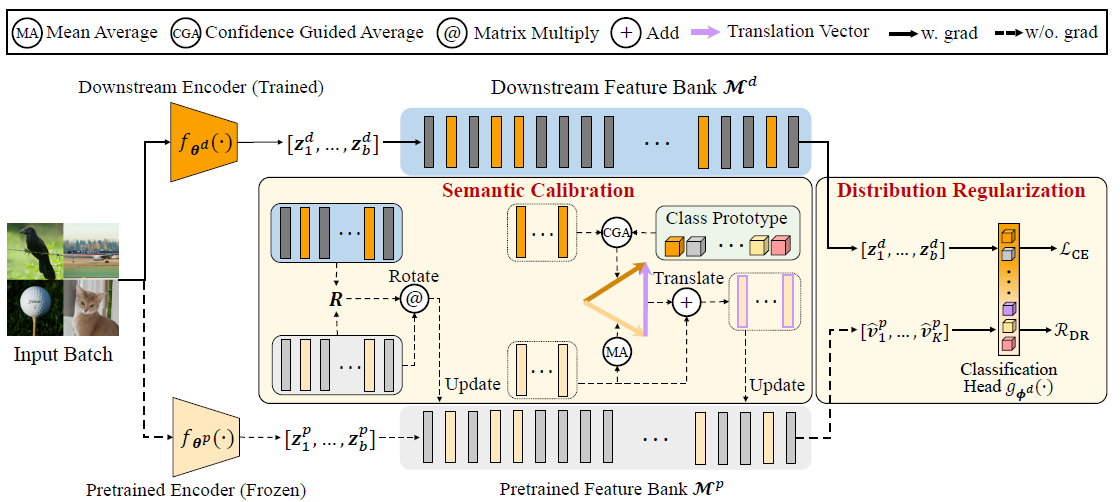
3.DR-Tune: Improving Fine-tuning of Pretrained Visual Models by Distribution Regularization with Semantic Calibration (Nan Zhou, Jiaxin Chen, and Di Huang)
为了解决预训练模型在微调阶段的过拟合现象,本文提出了一种基于分布正则化和语义校准的微调框架。分布正则化利用预训练模型输出的特征分布训练下游任务头,缓解了微调导致的过拟合问题。语义校准策略对齐了预训练和下游特征空间,降低了特征空间的语义偏移对正则化带来的影响。实验证明我们的微调框架可以与多种预训练模型适配,同时在性能上超越了现有的微调方法。
The visual models pretrained on large-scale benchmarks encode general knowledge and prove effective in building more powerful representations for downstream tasks.
This paper proposes a novel fine-tuning framework, namely Distribution Regularization with Semantic Calibration (DR-Tune), which aims to mitigate over-fitting during fine-tuning. It employs distribution regularization by enforcing the downstream task head to decrease its classification error on the pretrained feature distribution, which prevents it from being over-fitting while enabling sufficient training of downstream encoders. Furthermore, to alleviate the interference by semantic drift, we develop the Semantic Calibration (SC) module to align the global shape and the class centers of the pretrained and the downstream feature distributions. Extensive experiments on widely used image classification datasets show that DR-Tune consistently improves the performance when combing with various backbones under different pretraining strategies.
4.SA-BEV: Generating Semantic-Aware Bird's-Eye-View Feature for Multi-view 3D Object Detection (Jinqing Zhang, Yanan Zhang, Qingjie Liu, and Yunhong Wang)
以往的BEV三维目标检测方法将所有图像信息转换到BEV空间,这容易使占比很大背景信息淹没有用的前景信息。本文提出了一种只保留前景信息的检测模型,首先对图像特征进行前背景分割,之后在生成BEV特征时将背景信息滤除。在此基础上,BEV-Paste数据增强策略和多尺度跨任务检测头进一步提高了模型的泛化能力和检测精度。
The previous BEV 3D object detection methods convert all the image information to BEV space. It makes it easy that the large proportion of background information submerges the valid foreground information. In this paper, we propose a method that only preserves the foreground information. First, the image features are segmented into the foreground and background, and then the background information is filtered out when generating BEV features. Based on this, the BEV-Paste data augmentation strategy and the multi-scale cross-task head further improve the generalization ability and detection accuracy of the model.
