实验室5篇论文被国际计算机视觉与模式识别会议CVPR 2024接收
IRIP实验室今年共有5篇论文被国际计算机视觉会议CVPR 2024接收!CVPR是由IEEE主办的计算机视觉及人工智能等领域最具影响力和最重要的国际顶级会议之一。此次会议有11532篇的有效大会论文投稿,共录取2719篇论文,率用率为23.6%。此次会议将于美国西雅图召开。
接收论文简要介绍如下:
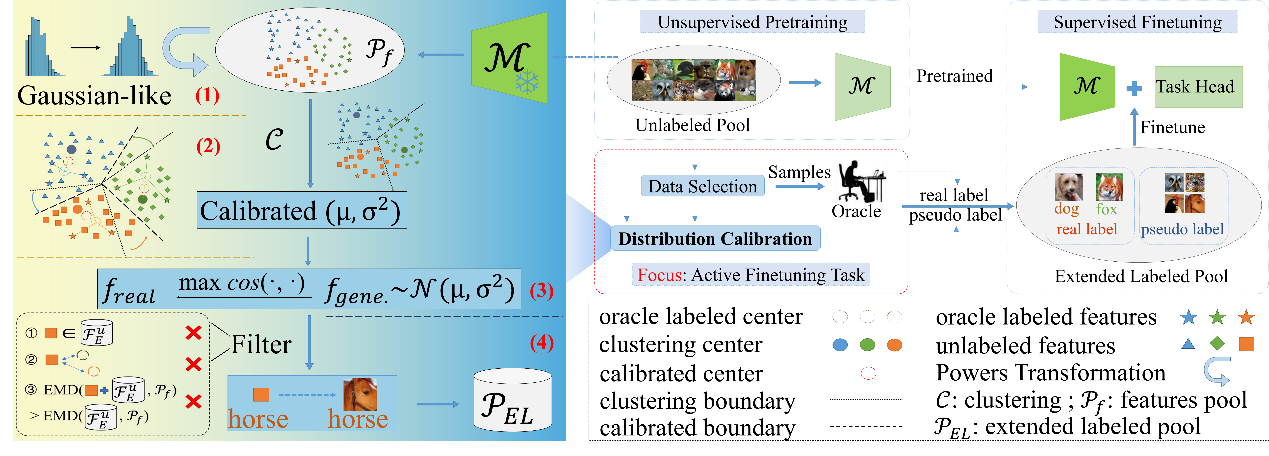
1. ActiveDC: Distribution Calibration for Active Finetuning. (Wenshuai Xu, Zhenghui Hu, Yu Lu, Jinzhou Meng, Qingjie Liu, and Yunhong Wang)
以往的主动微调任务使用有限数量的训练样本可能会导致分布有偏差,从而可能导致模型过度拟合。本文提出了一种称为 ActiveDC 的新方法,用于主动微调任务。首先,我们在连续可微空间中通过优化待选子集与整池数据之间的分布相似性来选择标注样本。其次,我们通过利用未标记池中的隐式类别信息来校准所选样本的分布。结果表明,ActiveDC 在所有图像分类任务中始终优于基准性能。当采样率较低时,改进尤为显著,性能提升高达 10%。
The pretraining-finetuning paradigm has gained popularity in various computer vision tasks. In this paradigm, the emergence of active finetuning arises due to the abundance of large-scale data and costly annotation requirements. Active finetuning involves selecting a subset of data from an unlabeled pool for annotation, facilitating subsequent finetuning. However, the use of a limited number of training samples can lead to a biased distribution, potentially resulting in model overfitting. In this paper, we propose a new method called ActiveDC for the active finetuning tasks. Firstly, we select samples for annotation by optimizing the distribution similarity between the subset to be selected and the entire unlabeled pool in continuous space. Secondly, we calibrate the distribution of the selected samples by exploiting implicit category information in the unlabeled pool. The feature visualization provides an intuitive sense of the effectiveness of our method to distribution calibration. We conducted extensive experiments on three image classification datasets with different sampling ratios. The results indicate that ActiveDC consistently outperforms the baseline performance in all image classification tasks. The improvement is particularly significant when the sampling ratio is low, with performance gains of up to 10%.
![]()
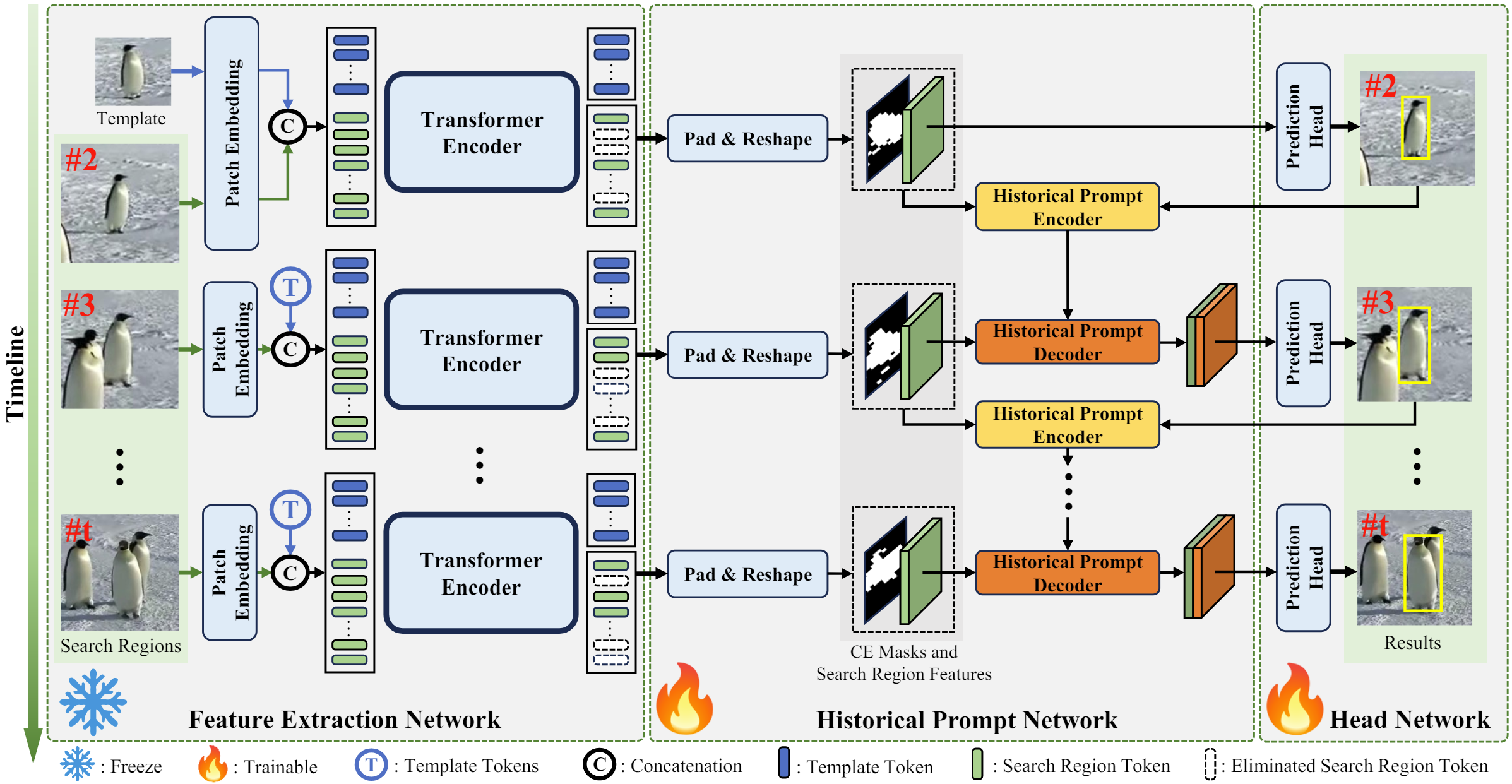
2.HIPTrack: Visual Tracking with Historical Prompts. (Wenrui Cai, Qingjie Liu, and Yunhong Wang)
目前流行的基于Transformer的单流跟踪器以及基于孪生网络的跟踪器都属于类孪生范式的跟踪器,此类跟踪器将视觉跟踪定义为模板与搜索区域的相似度匹配问题,忽略了目标在视频中丰富的上下文信息。而目前使用了历史信息的方法均有着历史信息不精确、不充分的问题,此外,目前的方法在引入历史信息时仍需要全参数量训练,加重了资源负担。针对以上问题,本文分析了类孪生范式的跟踪器在获得历史信息提示时的性能变化趋势,发现了目前的类孪生范式跟踪器仅需给予精确的历史提示即可大幅提升性能。基于以上分析,本文设计了历史提示网络,历史提示网络将精细化的目标位置信息和目标外观信息共同编码,并根据当前搜索区域自适应地生成提示;同时,本文基于历史提示网络提出了新的跟踪器HIPTrack,HIPTrack在仅需引入少量参数,且无需训练主干网络的情况下取得了目前的最佳性能表现。
The current popular Transformer-based one-stream trackers and Siamese-based trackers all follow Siamese paradigm that define visual tracking as the similarity matching problem between template and search region, ignoring the rich context information of the target in the video. However, current trackers using historical information all have the problem of inaccurate and insufficient historical information. In addition, all trackers still require full parameter training when introducing historical information, which increases the burden of resources. To solve the above problems, this paper analyzes the performance trend of Siamese-like trackers when they get accurate historical information, and finds that these trackers achieve great performance improvement. Based on the above analysis, this paper designs the historical prompt network, which encodes the refined target location information and target appearance information, and adaptively generates the prompt according to the current search region. At the same time, this paper proposes a new tracker called HIPTrack based on the historical prompt network. HIPTrack achieves the state-of-the-art performance by only introducing a small number of parameters without the need to train the entire model.
3.Generalizing 6-DoF Grasp Detection via Domain Prior Knowledge.(Haoxiang Ma, Modi Shi, Boyang Gao, and Di Huang)
本文重点研究6自由度抓取检测方法的泛化能力。基于学习的抓取检测方法可以利用从训练集中学习到的抓取分布来预测未见过物体的抓取姿态,但在遇到形状和结构差异较大的物体时,它们的性能往往会显著下降。为了增强抓取检测方法的泛化能力,我们结合了机器人抓取的领域先验知识,使其能够更好地适应具有显著形状和结构差异的物体。更具体地说,我们在训练阶段采用物理约束正则化,引导模型预测符合抓取物理规则的抓取姿态。对于在新物体上预测的不稳定抓取姿态,我们设计了一种基于投影接触图和接触分数联合优化方法,以在杂乱场景中对网络预测的抓取姿态进行细化。在GraspNet-1billion基准测试中进行的大量实验表明,在新物体集上获得了显著的性能提升,而真实世界的抓取实验也证明了我们的泛化6自由度抓取检测方法的有效性。
We focus on the generalization ability of the 6-DoF grasp detection method in this paper. While learning-based grasp detection methods can predict grasp poses for unseen objects using the grasp distribution learned from the training set, they often exhibit a significant performance drop when encountering objects with diverse shapes and structures. To enhance the grasp detection methods' generalization ability, we incorporate domain prior knowledge of robotic grasping, enabling better adaptation to objects with significant shape and structure differences. More specifically, we employ the physical constraint regularization during the training phase to guide the model towards predicting grasps that comply with the physical rule on grasping. For the unstable grasp poses predicted on novel objects, we design a contact-score joint optimization using the projection contact map to refine these poses in cluttered scenarios. Extensive experiments conducted on the GraspNet-1billion benchmark demonstrate a substantial performance gain on the novel object set and the real-world grasping experiments also demonstrate the effectiveness of our generalizing 6-DoF grasp detection method.

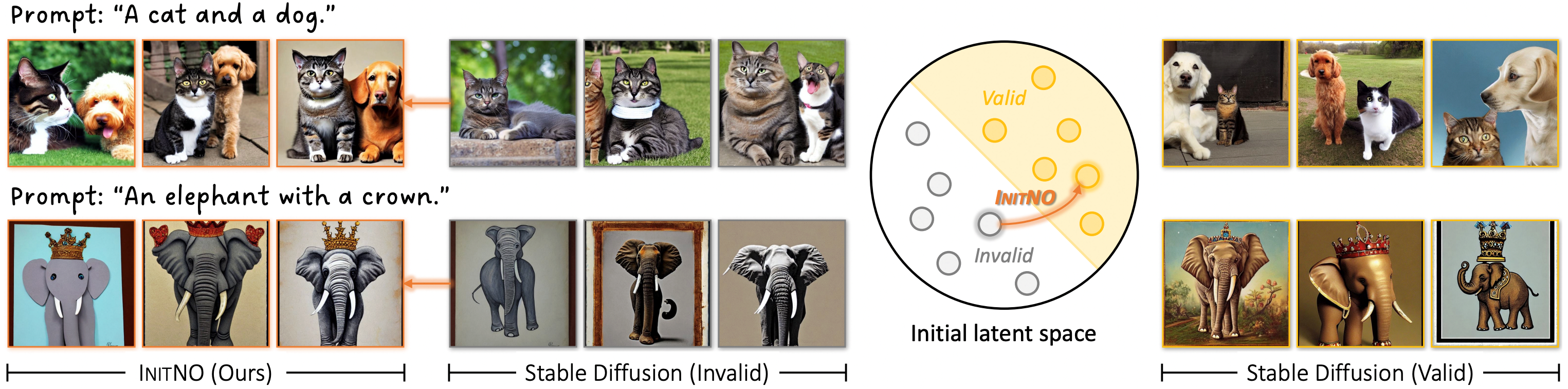
4.InitNo: Boosting Text-to-Image Difusion Models via nitial Noise Optimization.(Xiefan Guo, Jinlin Liu, Miaomiao Cui, Jiankai Li, Hongyu Yang, and Di Huang)
以Stable Diffusion为代表的扩散模型在文本生成图像的任务中展现出了令人惊喜的能力。然而,实现生成图像与所提供文本之间的精确对齐仍然是一项艰巨的挑战。本文将这一困难的根源追溯到无效的初始噪声,并提出了一种新颖的初始噪声优化方案来缓解该问题。对于给定文本,并非所有随机噪声都能有效合成语义对齐的图像。因此,我们设计了交叉注意力响应得分和自注意力冲突得分来评估初始噪声,将噪声空间分为有效和无效部分;进一步开发噪声优化算法,以将无效的初始噪声引导至有效区域。大量的实验表明我们的方法能够有效提升生成图像与给定文本的对齐度。
Recent strides in the development of diffusion models, exemplified by advancements such as Stable Diffusion, have underscored their remarkable prowess in generating visually compelling images. However, the imperative of achieving a seamless alignment between the generated image and the provided prompt persists as a formidable challenge. This paper traces the root of these difficulties to invalid initial noise, and proposes a solution in the form of Initial Noise Optimization (InitNO), a paradigm that refines this noise. Considering text prompts, not all random noises are effective in synthesizing semantically-faithful images. We design the cross-attention response score and the self-attention conflict score to evaluate the initial noise, bifurcating the initial latent space into valid and invalid sectors. A strategically crafted noise optimization pipeline is developed to guide the initial noise towards valid regions. Our method, validated through rigorous experimentation, shows a commendable proficiency in generating images in strict accordance with text prompts.
5.Leveraging Predicate and Triplet Learning for Scene Graph Generation. (Jiankai Li, Yunhong Wang, Xiefan Guo, Ruiie Yang, and Weixin Li)
场景图生成旨在识别实体并预测视觉场景中的关系三元组 <主体,谓词,客体>。鉴于即使在同一谓词中,<主体-客体>对也普遍存在较大的视觉变化,因此直接对这些谓词对进行建模和完善谓词表示具有相当大的挑战性,而这正是大多数现有场景图生成方法所采用的常见策略。我们观察到,相同三元组中的视觉变化相对较小,而且某些关系线索在同类三元组中是共享的,这有可能促进中的关系表示学习。此外,对于场景图生成任务中广泛研究的长尾问题,处理尾部谓词中有限类型和数量的三元组也至关重要。因此,我们在本文中提出了双粒度关系建模网络,同时利用粗粒度谓词信息和细粒度三元组信息。该网络利用双粒度约束提取谓词和三元组的上下文和语义,从两个粒度生成紧凑的表征,以促进关系识别。此外,模型还引入了双粒度知识转移策略,将头部谓词/三元组的变化转移到尾部谓词/三元组上,以丰富尾部类的模式多样性,从而缓解长尾问题。在 Visual Genome、Open Image 和 GQA 数据集的实验证明了我们的方法的有效性。
Scene Graph Generation (SGG) aims to identify entities and predict the relationship triplets <subject, predicate, object> in visual scenes. Given the prevalence of large visual variations of subject-object pairs even in the same predicate, it can be quite challenging to model and refine predicate representations directly across such pairs, which is however a common strategy adopted by most existing SGG methods. We observe that visual variations within the identical triplet are relatively small and certain relation cues are shared in the same type of triplet, which can potentially facilitate the relation learning in SGG. Moreover, for the long-tail problem widely studied in SGG task, it is also crucial to deal with the limited types and quantity of triplets in tail predicates. Accordingly, in this paper, we propose a Dual-granularity Relation Modeling (DRM) network to leverage fine-grained triplet cues besides the coarse-grained predicate ones. DRM utilizes contexts and semantics of predicate and triplet with Dual-granularity Constraints, generating compact and balanced representations from two perspectives to facilitate relation recognition. Furthermore, a Dual-granularity Knowledge Transfer (DKT) strategy is introduced to transfer variation from head predicates/triplets to tail ones, aiming to enrich the pattern diversity of tail classes to alleviate the long-tail problem. Extensive experiments demonstrate the effectiveness of our method, which establishes new state-of-the-art performance on Visual Genome, Open Image, and GQA datasets.

![]()