实验室6篇论文被国际计算机视觉与模式识别会议CVPR 2022接收.
IRIP实验室今年共有6篇论文被国际计算机视觉与模式识别会议CVPR 2022接收!CVPR是由IEEE主办的计算机视觉、模式识别及人工智能等领域最具影响力和最重要的国际顶级会议。CVPR官网显示,此次会议有超过8161篇的大会论文投稿,共录取2067篇论文,录取率约为25.33%。此次会议将于2022年6月在美国新奥尔良召开。
接收论文简要介绍如下:
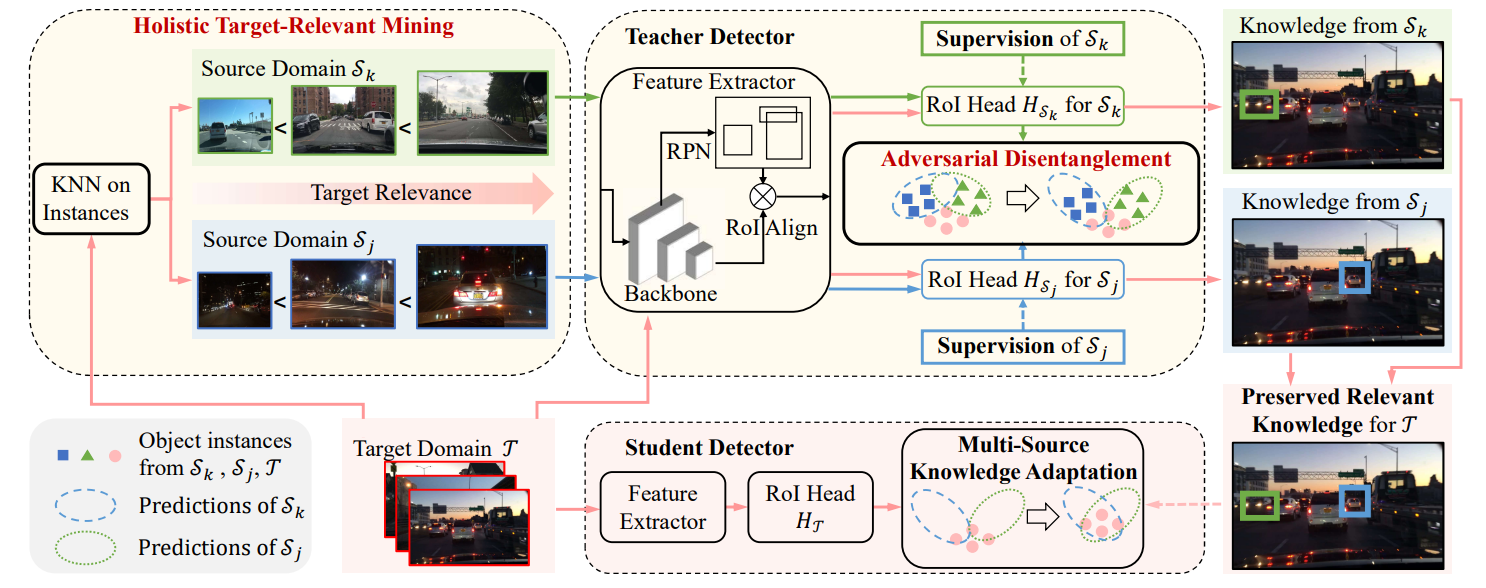
1.Target-Relevant Knowledge Preservation for Multi-Source Domain Adaptive Object Detection. (Jiaxi Wu, Jiaxin Chen, Mengzhe He, Yiru Wang, Bo Li, Bingqi Ma, Weihao Gan, Wei Wu, Yali Wang, Di Huang) (Oral)
针对多源域下的无监督领域自适应目标检测任务,本文提出了一种基于目标领域相关知识保存的知识蒸馏方法。其中教师模型使用了一种基于对抗的多源域解耦模块,以此在自适应过程中保存各个源域特有的知识。同时本文还提出了一种全局的目标领域相关性挖掘方法,使得源域数据根据其和目标域的相关性进行加权。通过以上方法,教师模型更能捕捉到目标领域相关的知识,有助于指导学生模型进行跨域自适应目标检测任务。大量实验证明了其优越性。
This paper proposes a novel teacher-student approach, namely target-relevant knowledge preservation (TRKP), to unsupervised multi-source domain adaptive object detection. The teacher network is equipped with an adversarial multi-source disentanglement (AMSD) module to preserve source domain-specific knowledge and simultaneously perform cross-domain alignment. Besides, a holistic target-relevant mining (HTRM) scheme is developed to re-weight the source images according to the source-target relevance. By this means, the teacher network is enforced to capture target-relevant knowledge, thus benefiting decreasing domain shift when mentoring object detection in the target domain. Extensive experiments are conducted on various widely used benchmarks with new state-of-the-art scores reported, highlighting the effectiveness.
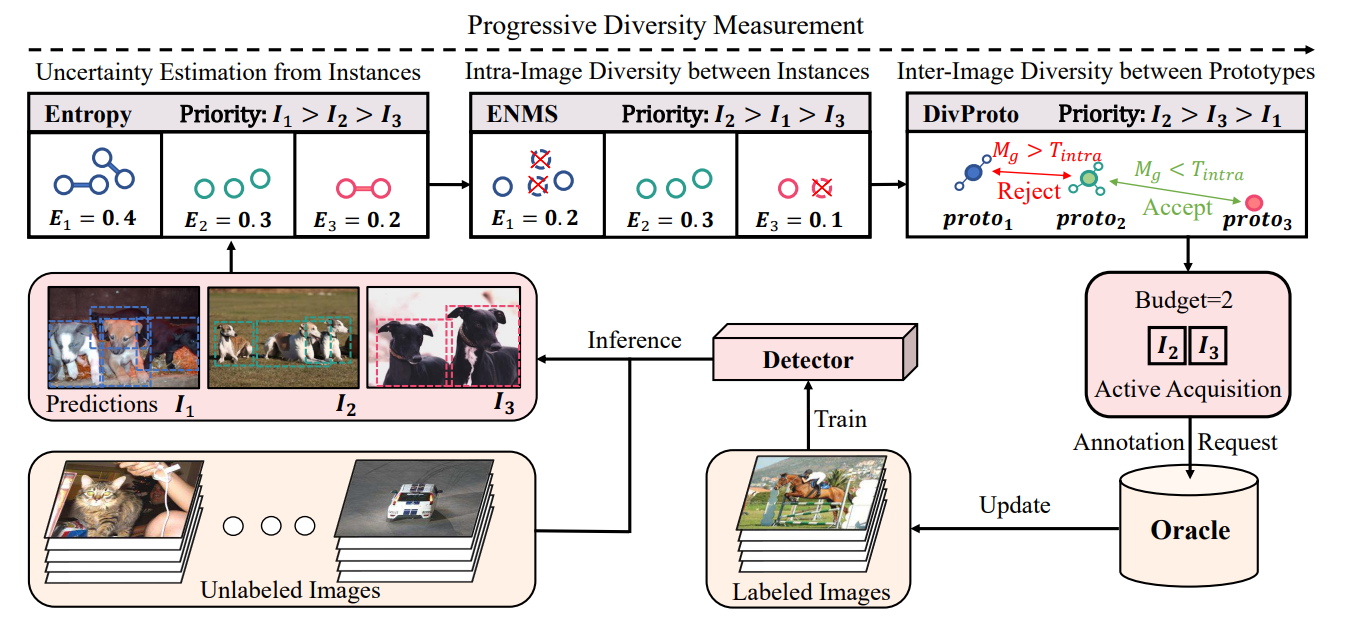
2.Entropy-based Active Learning for Object Detection with Progressive Diversity Constraint. (Jiaxi Wu, Jiaxin Chen, Di Huang)
本文提出了一种新的混合主动学习目标检测方法,在目标实例层面自底向上地同时考虑了不确定性和离散型。该方法以两阶段的形式来平衡计算复杂度。第一阶段提出了一种基于熵的非极大抑制方法,其在特征空间中去除冗余预测,再以此为基础评估图像的整体不确定性。第二阶段提出了一种离散原型策略,基于熵计算每张图像各个类别的原型向量,通过实现类别原型的类内离散性和类间离散性来保证采样图像间的离散型。大量实验证明了该方法的有效性。
This paper proposes a novel hybrid approach for active learning for object detection, where the instance-level uncertainty and diversity are jointly considered in a bottom-up manner. To balance the computational complexity, the proposed approach is designed as a two-stage procedure. At the first stage, an Entropy-based Non-Maximum Suppression (ENMS) is presented to estimate the uncertainty of every image, which performs NMS according to the entropy in the feature space to remove predictions with redundant information gains. At the second stage, a diverse prototype (DivProto) strategy is explored to ensure the diversity across images by progressively converting it into the intra-class and inter-class diversities of the entropy-based class-specific prototypes. Extensive experiments are conducted on MS COCO and Pascal VOC, and the proposed approach achieves state of the art results and significantly outperforms the other counterparts, highlighting its superiority.
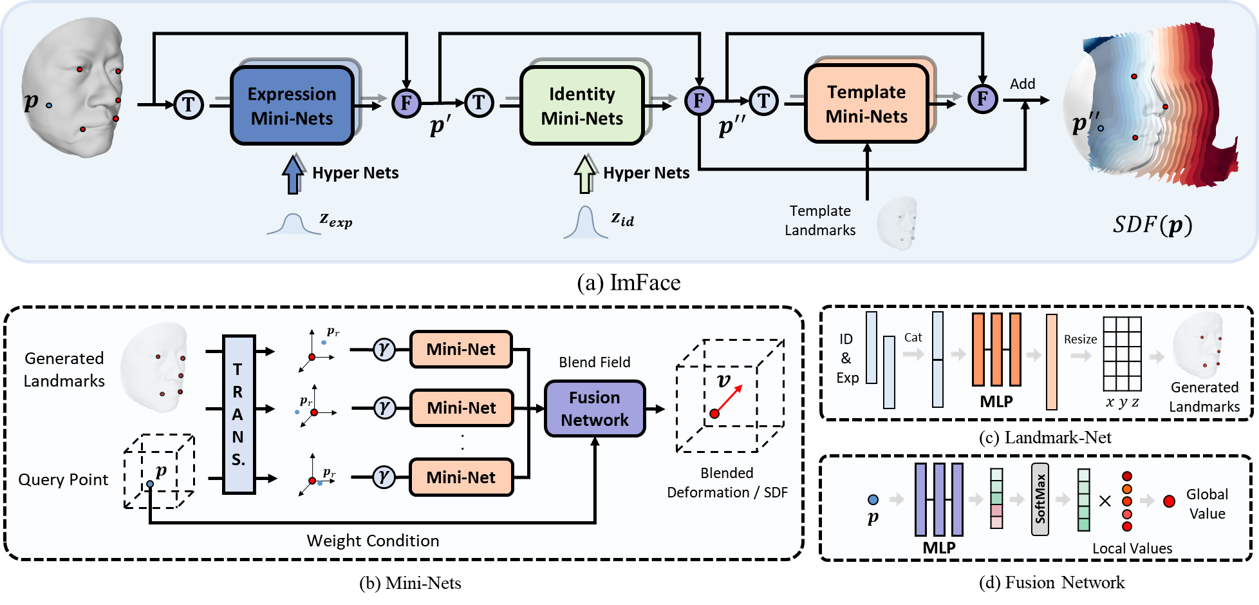
3.ImFace: A Nonlinear 3D Morphable Face Model with Implicit Neural Representations. (Mingwu Zheng, Hongyu Yang, Di Huang, Liming Chen)
高质量三维人脸建模是计算机视觉和计算机图形学在人脸相关应用上的核心内容。为了解决传统三维人脸模型依赖预对齐、复杂表情建模能力弱、人脸表面细节有限的问题,我们提出基于隐式神经表示的三维人脸模型,通过显式的形变解耦、动态的局部划分、专用的数据处理等设计,实现了完全基于隐表示的高质量三维人脸模型。实验证明我们的模型在重建任务上大幅度超过了目前主流的三维人脸模型。
Precise representations of 3D faces are beneficial to various computer vision and graphics applications. Due to the data discretization and model linearity, however, it remains challenging to capture accurate identity and expression clues in current studies. This paper presents a novel 3D morphable face model, namely ImFace, to learn a nonlinear and continuous space with implicit neural representations. It builds two explicitly disentangled deformation fields to model complex shapes associated with identities and expressions, respectively, and designs a Neural Blend-Field to learn sophisticated details by adaptively blending a series of local fields. In addition to ImFace, an effective preprocessing pipeline is proposed to address the issue of watertight input requirement in implicit representations, enabling them to work with common facial surfaces for the first time. Extensive experiments are performed to demonstrate the superiority of ImFace.
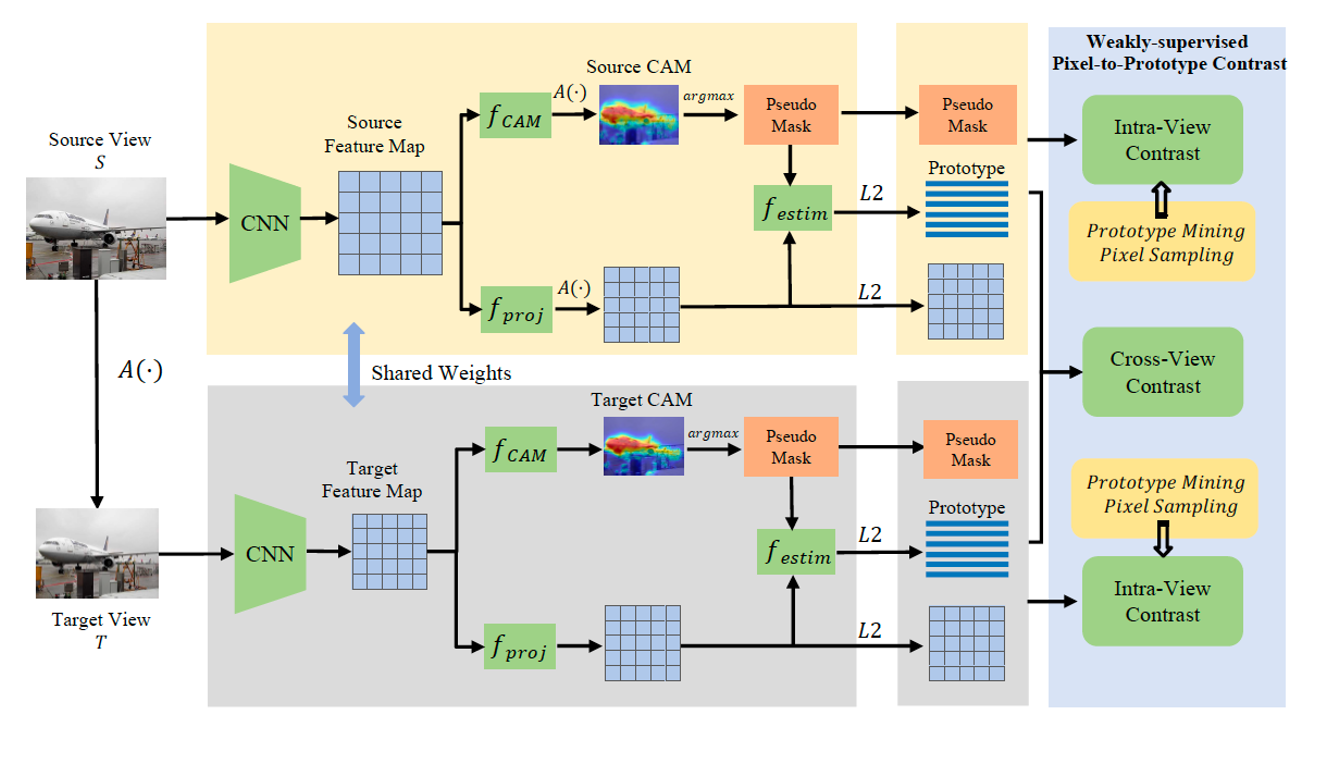
4.Weakly Supervised Semantic Segmentation by Pixel-to-prototype Contrast. (Ye Du, Zehua Fu, Qingjie Liu)
为了解决弱监督语义分割中,图像级监督和像素级监督之间的粒度不匹配问题,本文提出了一种弱监督像素到原型的密集对比学习方法,通过跨视图和视图内的对比,为分割任务提供了跨视图一致性和类内紧凑、类间分散约束。实验证明了该方法的有效性。
To solve the problem of granularity mismatch between image-level supervision and pixel-level supervision in weakly supervised semantic segmentation, a weakly supervised pixel-to-prototype contrastive learning method is proposed, which provides cross-view consistency and intra-class compactness and inter-class dispersion constraints for segmentation task through cross-view and intra-view contrast. Experiments have proved the effectiveness of the method.
5.Lagrange Motion Analysis and View Embeddings for Improved Gait Recognition. (Tianrui Chai, Annan Li, Shaoxiong Zhang, Zilong Li, Yunhong Wang)
步态被认为是包含了人体体型和运动信息的人体行走模式。但是,目前主流的基于表观的步态识别方法往往更多依赖人体的形状剪影图,很难去判断他们是否能准确的表示人体的运动信息。在这篇文章中,我们使用拉格朗日运动方程对人体行走进行了建模,并得出了在识别中二阶运动信息是必要的的结论。我们根据这个结论设计了一个二阶运动信息提取模块。同时,目前的步态识别方法很少考虑视角信息,我们在文章中提出了一个轻量级的视角嵌入方法。实验验证了我们方法的优越性。
Gait is considered the walking pattern of human body, which includes both shape and motion cues. However, the main-stream appearance-based methods for gait recognition rely on the shape of silhouette. It is unclear whether motion can be explicitly represented in the gait sequence modeling. In this paper, we analyzed human walking using the Lagrange's equation and come to the conclusion that second-order information in the temporal dimension is necessary for identification. We designed a second-order motion extraction module based on the conclusions drawn. Also, a light weight view-embedding module is designed by analyzing the problem that current methods to cross-view task do not take view itself into consideration explicitly. Experiments on CASIA-B and OU-MVLP datasets show the effectiveness of our method and some visualization for extracted motion are done to show the interpretability of our motion extraction module.

6.CAT-Det: Contrastively Augmented Transformer for Multi-modal 3D Object Detection. (Yanan Zhang, Jiaxin Chen, Di Huang)
本文提出了一种用于多模态3D目标检测的对比增强Transformer:CAT-Det,旨在解决多模态融合不足和缺乏有效的多模态数据增强的问题。CAT-Det由Pointformer分支、Imageformer分支和Cross-Modal Transformer模块联合编码模态内和模态间远程上下文,从而充分挖掘用于检测的多模态信息。此外,我们通过在点和物体级别上的分层对比学习提出了一种有效的单向多模态数据增强方法。在KITTI数据集上进行了实验,验证了其优越性。
This paper proposes a Contrastively Augmented Transformer for multi-modal 3D object Detection (CAT-Det), which aims to solve the problems of insufficient multi-modal fusion and lack of effective multi-modal data augmentation. CAT-Det uses Pointformer (PT) branch, Imageformer (IT) branch and Cross-Modal Transformer (CMT) module to jointly encode intra-modal and inter-modal long-range contexts, thus fully exploring multi-modal information for detection. Furthermore, we propose an effective One-way Multi-modal Data Augmentation (OMDA) approach via hierarchical contrastive learning at both the point and object levels. Extensive experiments on the KITTI benchmark show that CAT-Det achieves a new state-of-the-art, highlighting its effectiveness.
